
Monolith to Microservices: A Beginner's Guide to Architecture Evolution
Learn what microservices are, when to use them, and how they differ from monolithic architectures. A beginner-friendly guide covering bounded contexts, sagas, API gateways, and system design.
If you have spent any time in the software engineering world lately, you have probably heard the buzzword "Microservices". It seems like every large tech company has abandoned their old ways and moved to this shiny new architecture. But what does it actually mean? Are microservices just a hype train, or is there a genuine technical reason to adopt them?
In this comprehensive guide, we are going to break down the journey from a traditional monolithic architecture to a microservices-based system. We will explore the core concepts, the massive benefits, and importantly the hidden challenges that no one talks about until things break in production.
Whether you are a junior developer trying to understand system design or a senior engineer contemplating an architecture rewrite, this guide will give you a practical, human-friendly overview of what microservices truly are.
What is a Monolith, Anyway?
Before we can appreciate microservices, we need to understand the architecture they are meant to replace: the Monolith.
A monolithic application is a software system where all the code from the user interface, to the business logic, to the database access layer is bundled together into a single, indivisible unit. If you are building a simple e-commerce site, your product catalog, shopping cart, payment processing, and user management are all living in the exact same codebase, running in the same process, and usually connected to the same database.
The Good Things About Monoliths
Do not let the internet convince you that monoliths are inherently bad. In fact, for 90% of new projects, starting with a monolith is the right choice.
- Simple to Develop: You open your IDE, and all the code is right there.
- Simple to Test: You can run the entire application on your laptop with a single command. End-to-end testing is straightforward.
- Simple to Deploy: You build one artifact (like a
.dllor a.jaror a Docker container) and deploy it to a server. - Simple Debugging: Since everything runs in a single process, you can easily track a request from the user interface down to the database using your debugger.
The Breaking Point of a Monolith
So, if monoliths are so great, why do people move away from them? The problem arises when the application becomes massively successful.
As your engineering team grows from 5 to 50 developers, the monolithic codebase becomes a bottleneck.
- Deployment Fear: Every time someone merges a change, the entire application has to be rebuilt and deployed. If there is a bug in the "User Reviews" feature, it could crash the "Checkout" feature, taking down the whole business.
- Scaling Issues: If your "Search" feature gets a massive spike in traffic, you cannot just scale the search component. You have to scale the entire monolithic application, which is a massive waste of server resources.
- Tech Stack Lock-in: Are you stuck on an old version of a framework? Upgrading means upgrading the entire massive codebase at once, which can take months of painful effort.
When these pain points start costing the business real money and slowing down feature delivery, it is time to look at microservices. If you are looking to understand how systems grow to massive scale, check out my guide on scaling a system from zero to 10 million users.
What Are Microservices?
Microservices architecture is an approach where a large application is built as a suite of small, independently deployable services. Each service is built around a specific business capability and runs in its own isolated process.
Instead of having a single "E-commerce App," you break it down into:
- A
ProductCatalogService - An
OrderManagementService - A
PaymentService - A
UserAccountService
These services do not share code, and more importantly, they do not share databases. They communicate with each other over a network, typically using lightweight protocols like HTTP/REST or messaging queues like RabbitMQ or Kafka.

The Core Principles of Microservices
To truly "do" microservices, you need to adhere to a few strict principles.
1. Independent Deployability
This is the golden rule. You must be able to deploy the PaymentService to production without having to touch, deploy, or even think about the ProductCatalogService. If deploying one service requires you to deploy another service at the exact same time, you do not have microservices; you have a distributed monolith (which is the worst of both worlds).
2. Business Domain Focus
Services should be organized around business domains, not technical layers. You should not have a "Database Service" or a "UI Service." Instead, align your services with business capabilities. The Microsoft documentation on microservices does a fantastic job of explaining how Domain-Driven Design (DDD) is vital for defining these boundaries.
3. Data Encapsulation
Each microservice must own its own data. The OrderManagementService is the only entity allowed to read and write to the Orders database tables. If the UserAccountService needs to know about a user's recent orders, it cannot run a SQL query against the orders database. It must make a network request to the OrderManagementService's API.
This prevents the tight coupling that makes monoliths so hard to change. If the order team decides to switch from SQL Server to MongoDB, no other team needs to know or care, as long as the API remains the same. If database performance is a bottleneck in your current architecture, take a look at why database performance fails at schema design before blaming the monolith.
Why Make the Switch? The Massive Benefits
Moving to a distributed architecture is a massive undertaking. So, what is the payoff? Why do organizations invest millions of dollars into this transition?
1. Targeted Scaling
Imagine it is Black Friday. Everyone is browsing your e-commerce site, searching for deals. The ProductCatalogService is getting hammered with traffic, while the PaymentService is relatively quiet because people are just browsing.
With microservices, you can spin up 50 instances of the ProductCatalogService to handle the read traffic, while keeping the PaymentService at 2 instances. This targeted scaling is incredibly cost-efficient and allows you to optimize your cloud infrastructure.
2. Technology Freedom (Polyglot Programming)
In a microservices architecture, every service is an isolated black box. As long as the service honors its API contract, nobody cares what happens inside the box.
This means your teams can use the best tool for the job.
- The
PaymentServicemight be written in C# and ASP.NET Core because you need strong typing and enterprise reliability. - The
RecommendationServicemight be written in Python because it needs to leverage machine learning libraries. - The
InventoryServicemight use a blazing-fast Redis cache, while theUserAccountServicerelies on a traditional relational SQL database.
3. Team Autonomy and Velocity
There is a famous adage called Conway’s Law:
"Organizations which design systems ... are constrained to produce designs which are copies of the communication structures of these organizations."
Microservices embrace Conway’s Law. You can assign a small team of 5-7 developers to completely own the OrderManagementService. They can choose their own tech stack, establish their own release schedule, and deploy updates multiple times a day without coordinating with 50 other developers. This autonomy dramatically increases the speed at which you can deliver features to your users.
The Dark Side: Challenges of Microservices
This all sounds wonderful, right? You might be wondering why anyone would ever build a monolith again.
But microservices come with a steep price tag. When you break a monolith apart, you are trading in-memory complexity for network complexity. You are moving from a single system to a distributed system, and distributed systems are notoriously difficult to get right.
1. Network Unreliability and Latency
In a monolith, calling a function like codetoclarityService.GetUserDetails() happens in memory. It takes milliseconds and never fails unless the entire application crashes.
In a microservices architecture, GetUserDetails() is an HTTP network call. Networks fail. Packets drop. The target server might be restarting. You have to write code that handles these failures gracefully. You need to implement retries, circuit breakers, and timeouts. Suddenly, a simple data retrieval becomes a complex engineering problem.
2. Distributed Data Consistency
In a monolith, if a user places an order, you can deduct the inventory and save the order in a single SQL transaction. If either fails, the database rolls back, and data integrity is maintained.
With microservices, the OrderService saves the order, and the InventoryService manages the inventory. You cannot have a single database transaction span multiple services. This forces you to use complex patterns like Eventual Consistency and Sagas to ensure that data eventually matches up. Understanding these trade-offs between consistency and latency is crucial; I highly recommend reading up on the PACELC theorem to wrap your head around distributed data.
3. Operational Complexity
Deploying a monolith is easy. Deploying 30 microservices is an operational nightmare unless you have a world-class DevOps team.
You need:
- Automated CI/CD pipelines for every service.
- Container orchestration (like Kubernetes) to manage the thousands of running containers.
- Advanced logging and monitoring, because when a request spans 5 different services and then fails, you need to know exactly where the failure occurred. You will absolutely need proper traces and metrics, which you can learn about in my ultimate guide to .NET observability.
Code Example: Monolith vs. Microservice Communication
Let's look at a practical example of how code changes when you move to microservices.
Imagine a simple user registration flow where we create the user and then send a welcome email.
The Monolith Approach
In a monolith, the UserService and EmailService live in the same codebase. You simply inject the email service and call it.
public class UserService
{
private readonly IEmailService _emailService;
private readonly UserRepository _repository;
public UserService(IEmailService emailService, UserRepository repository)
{
_emailService = emailService;
_repository = repository;
}
public void RegisterUser(string email, string password)
{
// 1. Save user to database
var user = new User { Email = email, Password = password };
_repository.Save(user);
// 2. Send email directly (In-memory call)
_emailService.SendWelcomeEmail(email);
}
}
The Microservices Approach
In a microservices architecture, the UserService cannot directly call the EmailService class because it lives on a completely different server. Instead, the UserService might publish an event to a message broker like RabbitMQ.
public class CodeToClarityUserService
{
private readonly IMessageBroker _messageBroker;
private readonly UserRepository _repository;
public CodeToClarityUserService(IMessageBroker messageBroker, UserRepository repository)
{
_messageBroker = messageBroker;
_repository = repository;
}
public async Task RegisterUserAsync(string email, string password)
{
// 1. Save user to database
var user = new User { Email = email, Password = password };
_repository.Save(user);
// 2. Publish an event to the network
var userCreatedEvent = new UserCreatedEvent { Email = email };
await _messageBroker.PublishAsync("user.created", userCreatedEvent);
}
}
Notice how the microservice code is more resilient. If the email service is down, the user is still registered, and the event sits in the queue until the email service comes back online to process it. However, it also requires setting up and maintaining that message broker infrastructure.
The Strangler Fig Pattern: How to Migrate
If you have a massive monolith, you should never attempt a "Big Bang" rewrite where you try to rebuild the entire application as microservices from scratch. Big Bang rewrites almost always fail, cost millions of dollars, and halt new feature development for years.
Instead, use the Strangler Fig Pattern.
Named after a type of vine that slowly grows around an existing tree until it replaces it, this pattern involves incrementally extracting features from the monolith one by one.
Here is how you do it:
- Put an API Gateway in front: Direct all traffic through an API Gateway. Initially, the gateway routes 100% of the traffic to the monolith.
- Pick a small, low-risk domain: For example, the "User Reviews" feature.
- Build the new Microservice: Create the
ReviewServicewith its own database and functionality. - Reroute the traffic: Update the API Gateway to route all
/api/reviewsrequests to the new microservice, while everything else still goes to the monolith. - Repeat: Gradually extract more and more domains until the monolith is an empty shell, and you can finally turn it off.
For a deeper dive into these architectural patterns, Martin Fowler's foundational article on Microservices is mandatory reading for any developer starting this journey.
Deep Dive: Managing Data Consistency Across Microservices
Since data consistency is one of the biggest hurdles, let's explore it more deeply. When you break apart your monolith, you also break apart your database. This is a critical point that trips up many teams. If you share a single database across multiple services, you haven't actually built microservices you have built a distributed monolith.
The Shared Database Anti-Pattern
Why is sharing a database bad? Imagine the InventoryService and OrderService both read and write directly to an Items table in SQL Server. If the InventoryService team decides to rename a column or change the data type to optimize their queries, the OrderService suddenly breaks in production. This tight coupling violates the independent deployability principle.
To avoid this, each microservice must have its own private database. But how do you handle business transactions that span multiple services?
Introducing the Saga Pattern
In a distributed environment, you cannot rely on traditional ACID (Atomicity, Consistency, Isolation, Durability) transactions. Instead, you use the Saga Pattern.
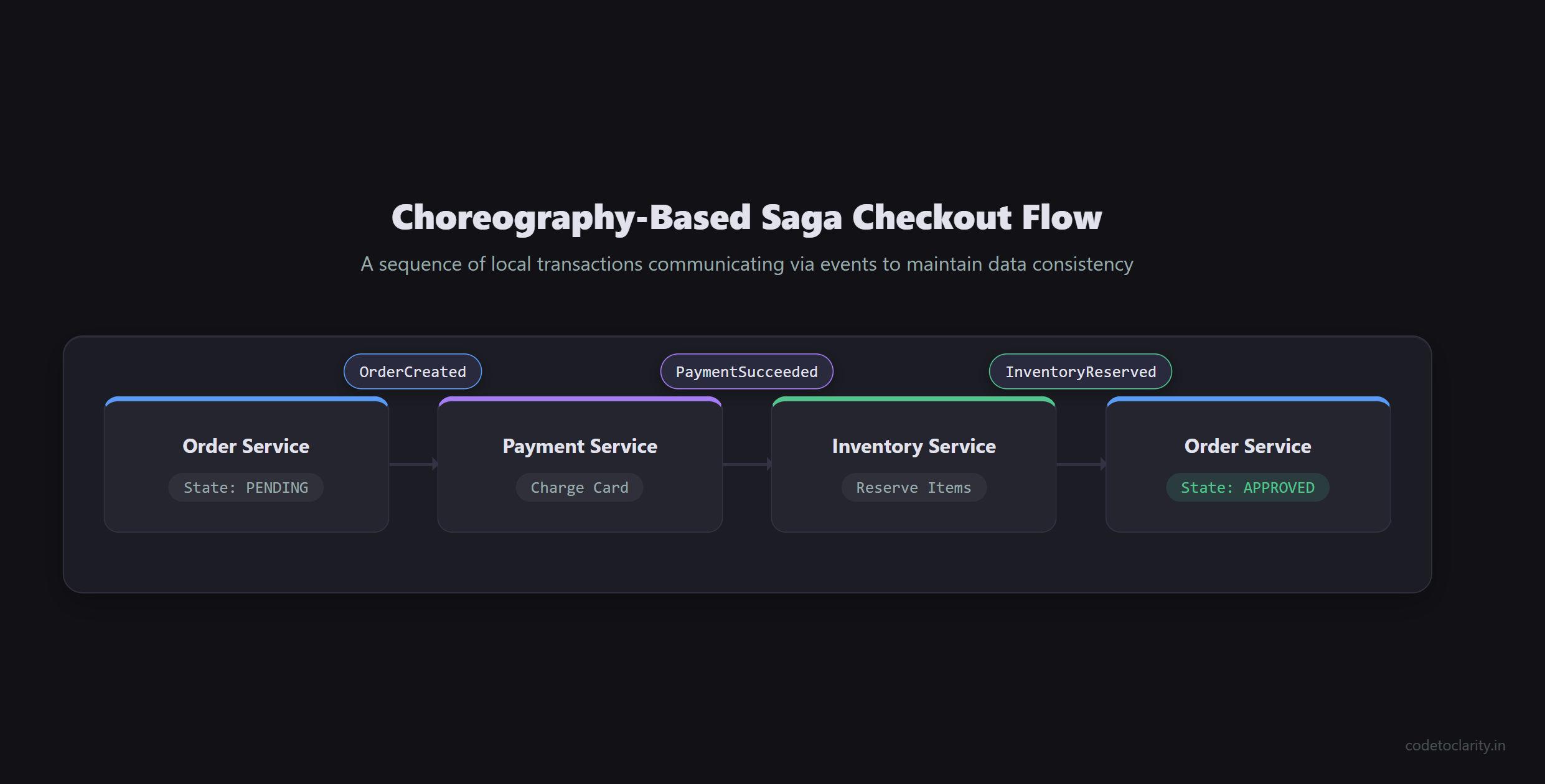
A Saga is a sequence of local transactions. Each service performs its local transaction and publishes an event. The next service listens to that event and performs its transaction.
Let's look at an e-commerce checkout flow using a choreography-based Saga:
- OrderService: Receives a checkout request. Creates an order in a
PENDINGstate. Publishes anOrderCreatedevent. - PaymentService: Listens for
OrderCreated. Attempts to charge the customer's credit card. If successful, it publishes aPaymentSucceededevent. - InventoryService: Listens for
PaymentSucceeded. Reserves the items in the warehouse. Publishes anInventoryReservedevent. - OrderService: Listens for
InventoryReserved. Updates the order state toAPPROVED.
Handling Failures with Compensating Transactions
What happens if step 3 fails because an item is out of stock? We cannot just rollback a SQL transaction because the payment has already been processed in a completely different database (and via a third-party payment gateway).
In a Saga, when a step fails, the service publishes a failure event. The preceding services must listen for this failure and execute compensating transactions to undo their work.
If the InventoryService fails:
- It publishes an
InventoryFailedevent. - The
PaymentServicelistens to this event and issues a refund to the customer's credit card. - The
OrderServicelistens to this event and updates the order state toREJECTED.
Writing this kind of logic requires careful thought and a mindset shift from traditional monolithic development.
Best Practices for Building Microservices
If you have decided that microservices are the right path for your organization, how do you ensure success? Over the years, the industry has developed several best practices for implementing distributed architectures effectively.
1. API Gateways
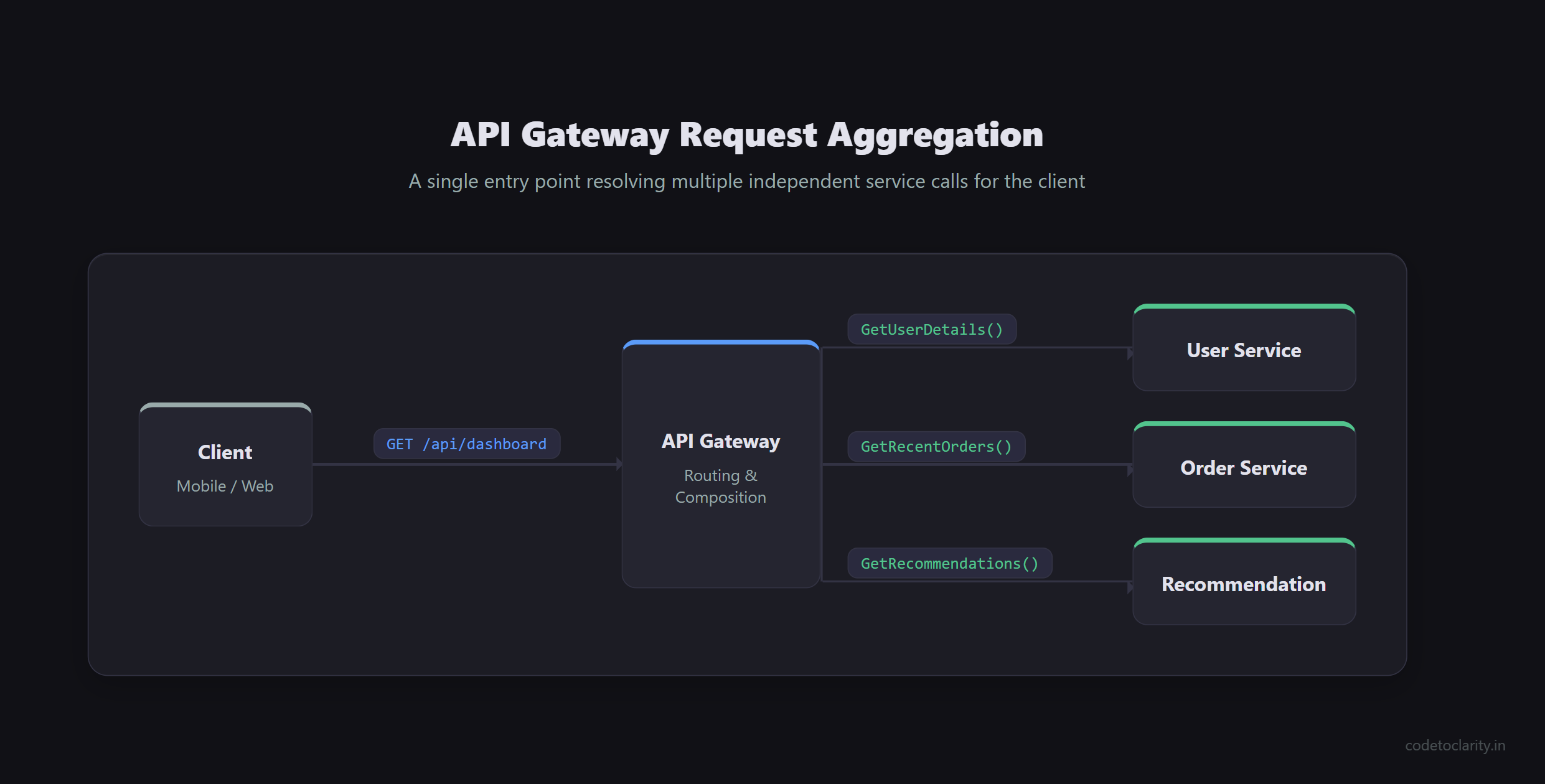
When a client application (like a mobile app or a React frontend) needs to fetch data from your backend, it should not have to know the IP addresses or hostnames of 15 different microservices. Furthermore, having the client make 15 separate HTTP requests over a mobile network will result in a terrible user experience.
An API Gateway acts as a single entry point for all client requests. The gateway handles routing, composition, and protocol translation. It can aggregate data from multiple services. For example, a single request to /api/dashboard might cause the gateway to fetch user details from the UserService, recent orders from the OrderService, and recommendations from the RecommendationService, merging them into a single JSON response for the client. The gateway is also the perfect place to implement cross-cutting concerns like authentication, SSL termination, and rate limiting.
2. Service Discovery
In a cloud environment, microservices are dynamic. Containers are constantly spinning up and down based on load. The IP address of the PaymentService might change 10 times a day.
How does the OrderService know where to find the PaymentService? You use a Service Discovery mechanism (like Consul, Eureka, or Kubernetes DNS). When a service starts up, it registers itself with the registry. When another service needs to communicate, it asks the registry for the current network location of the target service.
3. Centralized Logging and Distributed Tracing
As mentioned earlier, debugging a distributed system is incredibly difficult. If a user complains that their checkout failed, you need to know exactly which microservice caused the error.
You must implement centralized logging (e.g., the ELK stack: Elasticsearch, Logstash, Kibana, or tools like Datadog). Every microservice should forward its logs to a central repository.
Furthermore, you need Distributed Tracing. When a request enters the API Gateway, it should be assigned a unique TraceId (or CorrelationId). This ID must be passed along in the HTTP headers of every subsequent microservice call. If a failure occurs deep in the call chain, you can query your logging system for that specific TraceId and see the exact path the request took through your entire architecture.
4. Resilient Communication (Circuit Breakers)
When Service A calls Service B, and Service B is experiencing severe latency, Service A will likely sit there waiting for a response. If Service A receives high traffic, it will quickly exhaust its own thread pool waiting for Service B, causing Service A to crash as well. This is known as a cascading failure.
To prevent this, implement the Circuit Breaker Pattern using libraries like Polly (in .NET) or Resilience4j. If a certain number of requests to Service B fail or time out, the circuit "breaks" (opens). Subsequent requests from Service A will immediately fail fast without even attempting the network call, giving Service B time to recover. After a cooling-off period, the circuit allows a few test requests through to see if Service B is healthy again.
5. Asynchronous Messaging Over Synchronous Calls
While REST APIs are great, relying too heavily on synchronous HTTP calls creates tight coupling and fragility. If Service A requires an immediate response from Service B to function, Service A is fundamentally dependent on the uptime of Service B.
Whenever possible, prefer asynchronous messaging using queues or event streams (RabbitMQ, Azure Service Bus, Apache Kafka). If the CodeToClarityUserService publishes an event that a new user signed up, the EmailService can pick it up whenever it is ready. If the EmailService crashes, the message sits safely in the queue until the service is restarted. This dramatically improves the resilience of your entire system.
The Role of Domain-Driven Design (DDD)
We touched on aligning services with business capabilities, but how do you actually identify those capabilities? This is where Domain-Driven Design (DDD) comes in. DDD is a software design approach that focuses on modeling the software to match the real-world business domain.
In DDD, you define Bounded Contexts. A Bounded Context is a clear boundary within which a particular domain model is defined and applicable.
For instance, the concept of a "Product" means very different things to different parts of the business.
- To the Sales team, a Product is all about price, descriptions, and high-quality images.
- To the Shipping team, a Product is all about weight, dimensions, and warehouse location.
In a monolith, developers often try to create a single, massive Product class that satisfies every department, leading to a bloated and complex entity. In a microservices architecture guided by DDD, you create multiple Product models tailored to their specific bounded contexts. The CatalogService has a Product model focused on sales data, while the ShippingService has a Product model focused on logistics. This separation of concerns is the true secret to building maintainable microservices.
Moving Forward: The Modular Monolith Alternative
If you have read this far and feel overwhelmed by Sagas, API Gateways, and Service Discovery, you are not alone. The operational complexity of microservices is staggering.
Is there a middle ground? Yes. The Modular Monolith.
A modular monolith is a single deployable application (a monolith) that is strictly organized into independent modules internally. It enforces boundaries at the code level rather than the network level. You use namespaces or separate assemblies to ensure that the Order module cannot directly access the database of the User module.
The modular monolith gives you the benefits of clean, separated code and domain alignment, without the nightmare of distributed systems operations. If the application ever scales to the point where you truly need microservices, extracting a well-defined module into a separate service is exponentially easier than untangling a "big ball of mud" monolith.
Conclusion
The evolution from monolith to microservices is not merely a technical upgrade; it is a fundamental shift in how an organization builds, ships, and thinks about software. It is a journey from simplicity to complexity, undertaken strictly to achieve massive scale and organizational agility.
Microservices are a powerful architecture, but they demand a high level of engineering maturity. Before taking the leap, ensure you have the automated testing, CI/CD pipelines, and DevOps capabilities required to tame the beast. Start with a solid monolith, modularize it, and let your actual pain points (not industry hype) guide your architectural decisions.

Kishan Kumar
Software Engineer / Tech Blogger
A passionate software engineer with experience in building scalable web applications and sharing knowledge through technical writing. Dedicated to continuous learning and community contribution.